Thu Apr 10 01:13:27 PM +08 2025 #14 ✎
2016 on one's own
2016 on one's own


Первая весенняя свежесть, +12

1936
There you have it: some of the weirdest things in the Linux kernel's git history. There are 1,549 octopus merges, one of which has 66 parents. The most heavily diverged merge has 22,445,760 lines of diff, though it's a bit of a technicality because it shares no history with the rest of the repo. The kernel has four separate "initial" commits, one of which was a mistake. None of this will show up in the vast majority of git repos, but all of it is well within git's design parameters.
Above all, you do not let your tests drive your design, you let your design drive your tests! The design is going to point you in the right direction of what layer in the MVC cake should get the most test frosting. When you stop driving your design first, and primarily, through your tests, your eyes will open to much more interesting perspectives on the code. The answer to how can I make it better, is how can I make it clearer, not how can I test it faster or more isolated. The design integrity of your system is far more important than being able to test it any particular layer. Stop obsessing about unit tests, embrace backfilling of tests when you're happy with the design, and strive for overall system clarity as your principle pursuit.

Unfortunately, SawStart is one-use-only. Once started, the blade cannot be stopped, and must be replaced with a fresh blade while the running one is carefully disposed of.
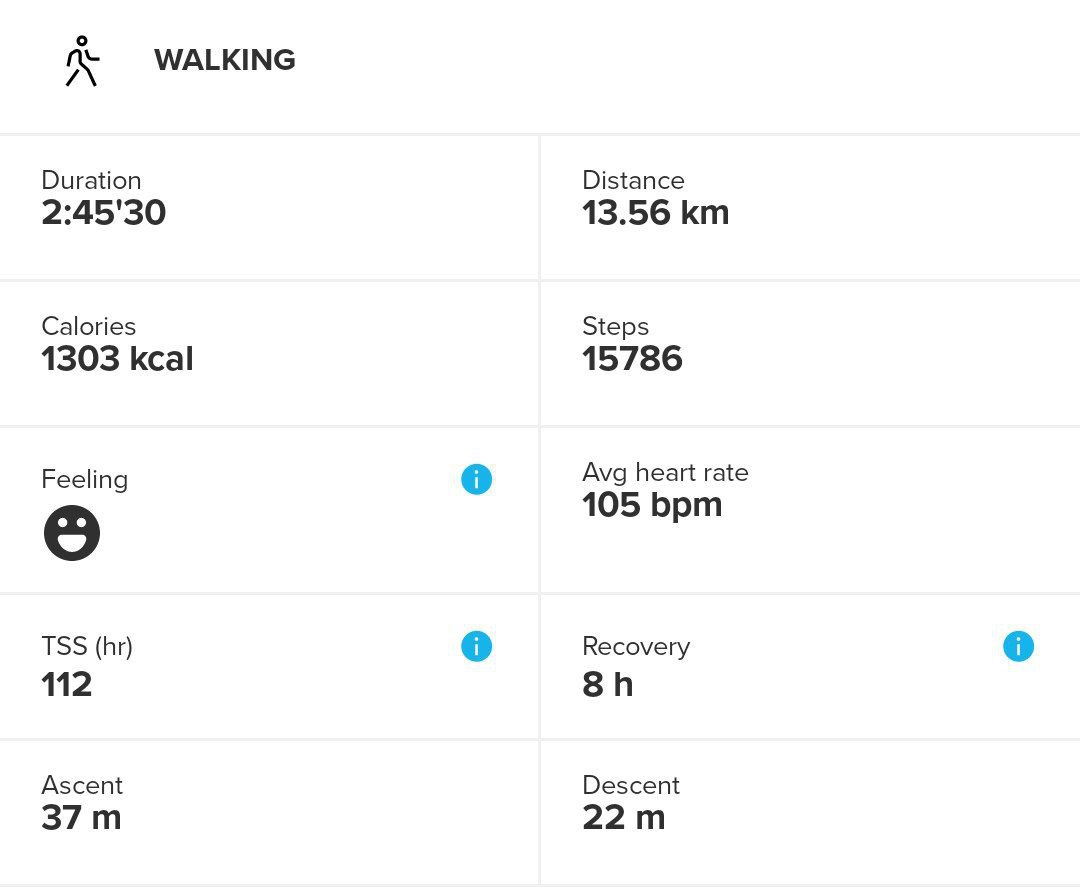
Long Aerobic
Про это пишет Хэмингуэй в «Празднике, который всегда с тобой»: «Радостно было спускаться по длинным маршам лестницы, сознавая, что ты хорошо поработал. Я всегда работал до тех пор, пока мне не удавалось чего-то добиться, и всегда останавливал работу, уже зная, что должно произойти дальше. Это давало мне разгон на завтра».

Vibing

Лайков не будет)
Хочется, конечно, чтобы здесь было всегда красиво. Но будет, как будет. 😂 И нужно проверить несколько гипотез. https://natureofcode.com/

Космос наш ждёт
Пифагорейское