Mon Jun 02 10:30:25 AM +08 2025 #39 ✎
Feeling stronger
Feeling stronger
$ python benchpop.py Size: 1000 - With: 0.0015s, 10318 comps | Without: 0.0018s, 16850 comps Size: 2000 - With: 0.0048s, 22672 comps | Without: 0.0042s, 37745 comps Size: 5000 - With: 0.0110s, 63319 comps | Without: 0.0120s, 107652 comps Size: 10000 - With: 0.0206s, 136634 comps | Without: 0.0276s, 235294 comps Size: 20000 - With: 0.0454s, 293288 comps | Without: 0.0583s, 510657 comps Oh, there it is. 🙄
$ python bench.py With siftdown inlined: 3.995546 seconds, Comparisons: 1648612 Without siftdown: 3.329431 seconds, Comparisons: 1882563 🫣
$ python bench.py With _siftdown: 6.305621 seconds, Comparisons: 1649692 Without _siftdown: 5.422437 seconds, Comparisons: 1880839 🤔
I am confused. 🧠
def _siftup(heap, pos):
endpos = len(heap)
startpos = pos
newitem = heap[pos]
# Bubble up the smaller child until hitting a leaf.
childpos = 2*pos + 1 # leftmost child position
while childpos < endpos:
# Set childpos to index of smaller child.
rightpos = childpos + 1
if rightpos < endpos and not heap[childpos] < heap[rightpos]:
childpos = rightpos
# Move the smaller child up.
heap[pos] = heap[childpos]
pos = childpos
childpos = 2*pos + 1
# The leaf at pos is empty now. Put newitem there, and bubble it up
# to its final resting place (by sifting its parents down).
heap[pos] = newitem
_siftdown(heap, startpos, pos)fuzz@workstation:~/code/rust_stuff/heap$ python bench.py
Heapify Performance Comparison (10 runs on list of 10,000 items):
With _siftdown: 0.030211 seconds
Without _siftdown: 0.011579 secondsYeah. I guess swapping two elements of slice is just faster than assigning one to another through = and pointing this values by index. No matter how many compare operations we can avoid.
Ok, here is the trick in Python's heap structure implementation that allows us to cut amount of comparison when sifting up items in the heap. https://github.com/python/cpython/blob/3.13/Lib/heapq.py#L278 We don't compare parent value with the children when sifting it up, assuming that item which is taken from the leaf will end up somewhere near the leaf. The idea (D.Knuth, Art of Programming, Volume 3) is to sift item through smallest of the children (and shifting smallest child towards the root on each step) to the leaf without swapping it in a process, then assign it to the leaf, and then sift it down to the proper place. Doing it this way must reduce amount of "compare" operations, because sifting item down to it place from the leaf is shorter path than the sifting it up to its location towards the leaf. It is low price to don't stop ("break" the loop) on proper location, but go down to the leaf with low cost operations and then go a little bit up comparing values. I know I have formulated this idea twice already. :-) Here is the third time: we make long path cheaper, according the heuristics about nature of the value we are sifting through the heap. Now, here is my research. I had wrote a little bit of code in Rust, playing with the heap. I am 37 years old programmer, but never played with the heap data structure. Oh, boy, brothers. Just having some fun here. And I've tested and benchmarked some code. And... idk, but my benchmarks in Rust said that "non-optimized" version when we swapping items towards the leaf and breaking the loop when we arrived is faster. Is this compiler optimizations? Some low-level stuff? I am not really into that. Maybe I made a mistake. https://github.com/fuzz88/rust_stuff/blob/master/heap/src/main.rs#L73 test tests::bench_heapify_not_optimized ... bench: 2,796.01 ns/iter (+/- 54.45) test tests::bench_heapify_optimized ... bench: 6,668.45 ns/iter (+/- 182.72) Just a memo to myself: benchmark critical parts, make decisions based on the data. Or just use "good enough" stuff for the task. I will call it a day.
"Be patient. Your future will come to you and lie down at your feet like a dog who knows and likes you no matter what you are."

...And Justice for All (1979)
What is good style? Good style in any language consists of code that is: Understandable Reusable Extensible Efficient Easy to develop and debug It also helps ensure correctness, robustness, and compatibility. Maxims of good style are: Be explicit Be specific Be concise Be consistent Be helpful (anticipate the reader's needs) Be conventional (don't be obscure) Build abstractions at a usable level Allow tools to interact (referential transparency) Know the context when reading code: Who wrote it and when? What were the business needs? What other factors contributed to the design decisions?


123
123
vo2max

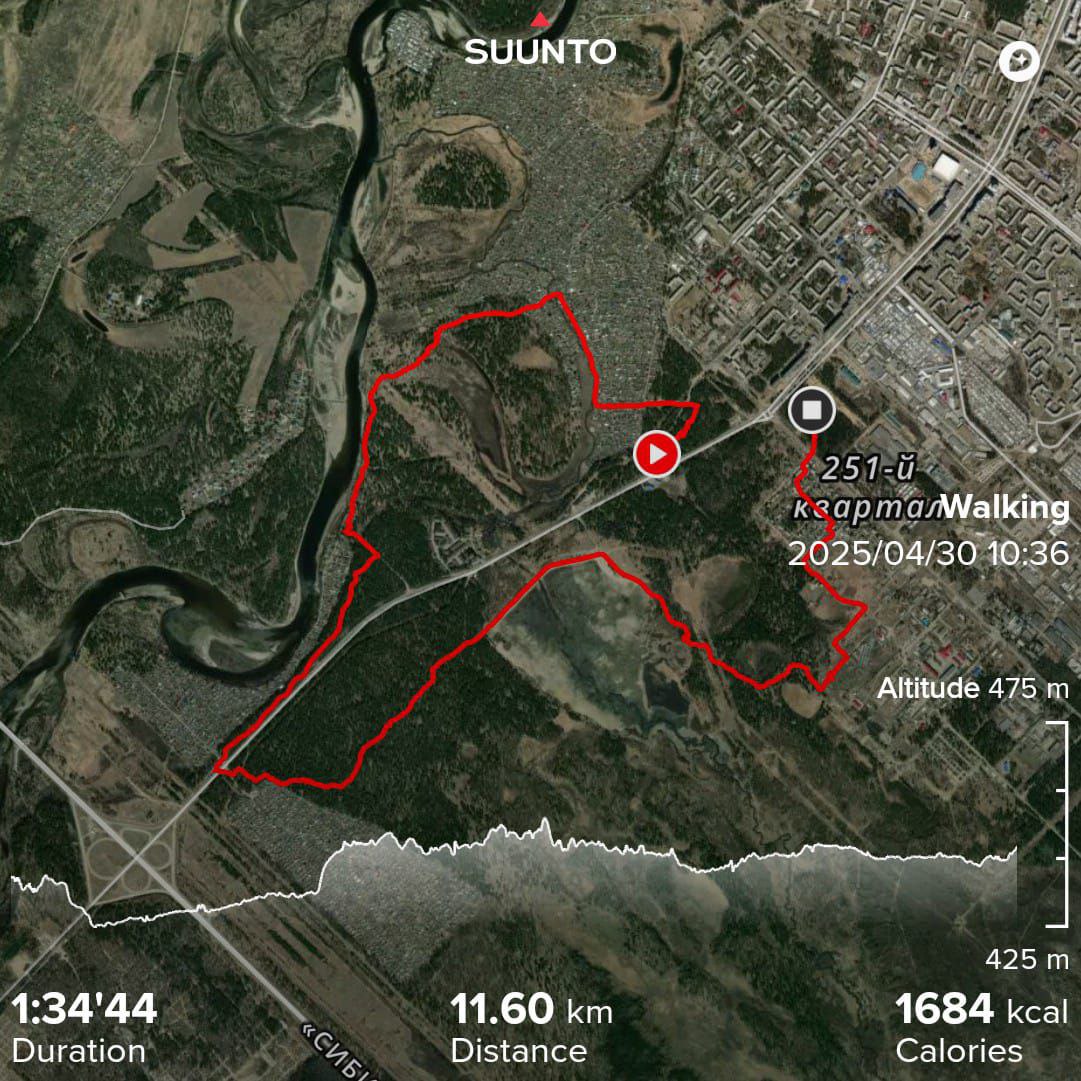
well tapered
When you ignore convention, you must be ready to stand your ground.
¯\_(ツ)_/¯
In computer programming our basic building block has an associated time grain of less than a microsecond, but our program may take hours of computation time. I do not know of any other technology covering a ratio of 10¹⁰ or more: the computer, by virtue of its fantastic speed, seems to be the first to provide us with an environment where highly hierarchical artefacts are both possible and necessary. This challenge, viz. the confrontation with the programming task, is so unique that this novel experience can teach us a lot about ourselves. It should deepen our understanding of the processes of design and creation, it should give us better control over the task of organizing our thoughts.
Как вы видите даже одна операция выделения памяти может стать узким местом, если она выполняется внутри часто вызываемой логики. В играх динамическое выделение памяти в большинстве случаев запрещено, вам 95% завернут такой код на ревью. Без веских на такое действие причин выделять память где хочется нельзя. Все, что может быть выделено, должно быть выделено до старта уровня.

Verba/Salix acutifolia
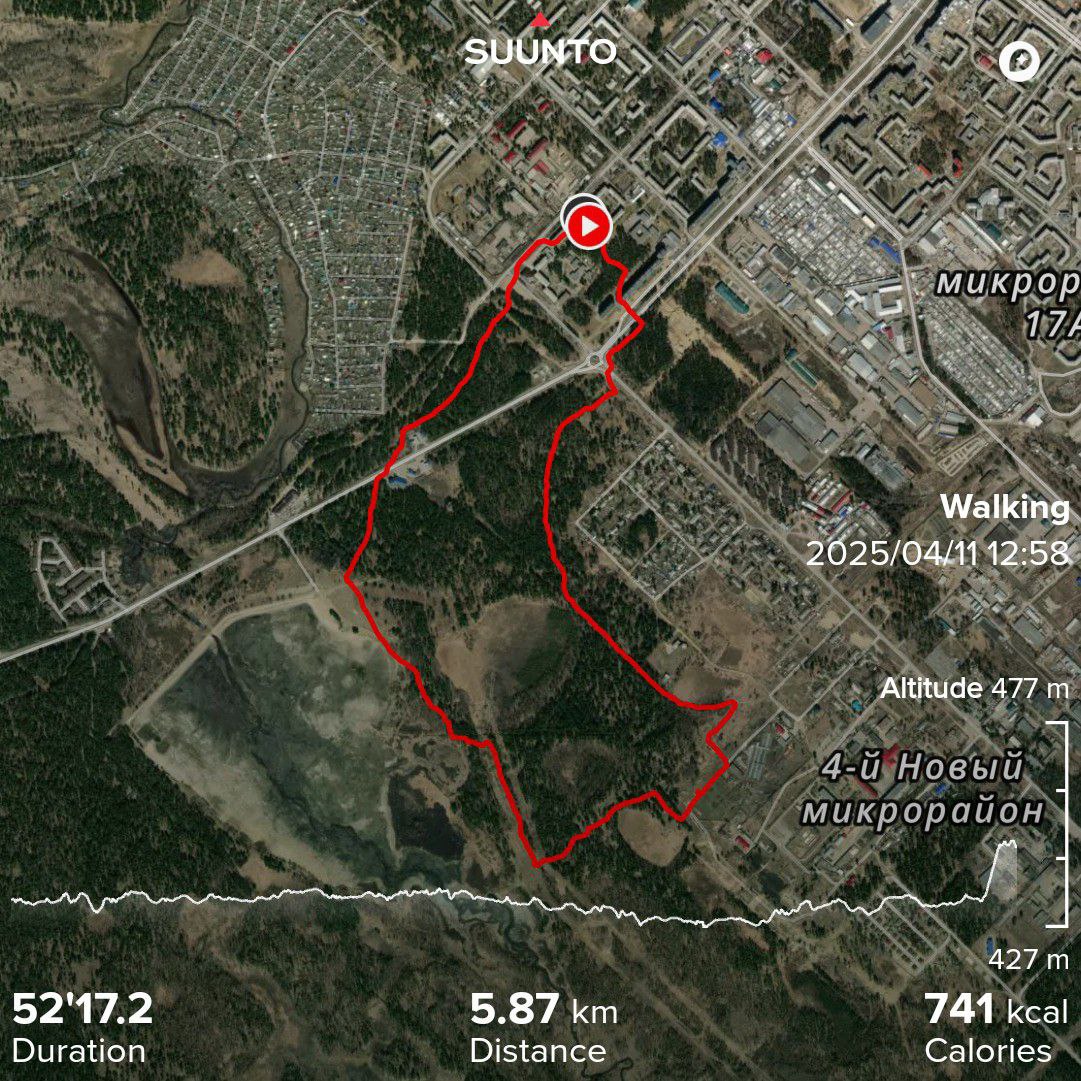
Run/walk